Introduction
Like many of my software-engineering peers, my experience has been rooted in traditional Java web applications, leveraging Java EE or Spring stacks running in a web application container such as Tomcat or Jetty. While this model has served well for most projects I’ve been involved in, recent trends in technology–among them, microservices, reactive UIs and systems, and the so-called Internet of Things–have piqued my interest in alternative stacks and server technologies.
Happily, the Java world has kept up with these trends and offers a number of alternatives. One of these, the Vert.x project, captured my attention a few years ago. Plenty of other articles extol the features of Vert.x, which include its event loop and non-blocking APIs, verticles, event bus, etc. But above all of those, I’ve found in toying around with my own Vert.x projects that the framework is simply easy to use and fun.
So naturally I was excited when one of my co-workers and I recognized a business case that Vert.x was ideally suited for. Our company is a Java and Spring shop that is moving from a monolithic to a microservices architecture. Key to our new architecture is the use of an event log. Services publish their business operations to the event log, and other services consume them and process them as necessary. Since our company’s services are hosted on Amazon Web Services, we’re using Kinesis as our event log implementation.
Our UI team has expressed interest in being able to enable our web UIs to listen for Kinesis events and react to them. I’d recently created a POC that leveraged Vert.x’s web socket implementation, so I joined forces with a co-worker who focused on our Kinesis Java consumer. He spun up a Vert.x project and integrated the consumer code. I then integrated the consumers with Vert.x’s event bus, and created a simple HTML page that, via Javascript and web sockets, also integrated with the event bus. Between the two of us, we had within a couple of hours created an application rendered an HTML page, listened to Kafka, and pushed messages to be displayed in real-time in the browser window.
I’ll show you how we did it. Note that I’ve modified our implementation for the purposes of clarity in this article in the following ways:
- This article uses RabbitMQ rather than Kinesis. The latter is proprietary to AWS, whereas RabbitMQ widely used and easy to spin up and develop prototypes against. While Kinesis is considered an event log and RabbitMQ a message queue, for our purposes their functionality is the same.
- I’ve removed superfluous code, combined some classes, and abandoned some best practices (e.g. using constants or properties instead of hard-coded strings) to make the code samples easier to follow.
Other than that and the renaming of some classes and packages, the crux of the work remains the same.
The Task at Hand
First, let’s take a look at the overall architecture:

Figure 1
At the center of the server architecture is RabbitMQ. On the one side of RabbitMQ, we have some random service (represented in the diagram by the grey box labelled Some random service) that publishes messages. For our purposes, we don’t care what this service does, other than the fact that it publishes text messages. On the other side, we have our Vert.x service that consumes messages from RabbitMQ. Meanwhile, a user’s Web browser loads an HTML page served up by our Vert.x app, and then opens a web socket to register itself to receive events from Vert.x.
We care mostly what happens within the purple box, which represents the Vert.x service. In the center, you’ll notice the event bus. The event bus is the “nervous system” of any Vert.x application, and allows separate components within an application to communicate with each other. These components communicate via addresses, which are really just names. As shown in the diagram, we’ll use two addresses: service.ui-message and service.rabbit.
The components that communicate via the event bus can be any type of class, and can be written in one of many different languages (indeed, Vert.x supports mixing Java, Javascript, Ruby, Groovy, and Ceylon in a single application). Generally, however, these components are written as what Vert.x calls verticles, or isolated units of business logic that can be deployed in a controlled manner. Our application employs two verticles: RabbitListenerVerticle and RabbitMessageConverterVerticle. The former registers to consume events from RabbitMQ, passing any message it receives to the event bus at the service.rabbit address. The latter receives messages from the event bus at the service.rabbit address, transforms the messages, and publishes them to the service.ui-message address. Thus, RabbitListenerVerticle‘s sole purpose is to consume messages, while RabbitMessageConverterVerticle‘s purpose is to transform those messages; they do their jobs while communicating with each other–and the rest of the application–via the event bus.
Once the transformed message is pushed to the service.ui-message event bus address, Vert.x’s web socket implementation pushes it up to any web browsers that have subscribed with the service. And really… that’s it!
Let’s look at some code.
Maven Dependencies
We use Maven, and so added these dependencies to the project’s POM file:
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-core</artifactId>
<version>3.3.3</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-web</artifactId>
<version>3.3.3</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-web-templ-handlebars</artifactId>
<version>3.3.3</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-rabbitmq-client</artifactId>
<version>3.3.3</version>
</dependency>
The first dependency, vertx-core, is required for all Vert.x applications. The next, vertx-web, provides functionality for handling HTTP requests. vertx-web-templ-handlebars augments enhances vertx-web with Handlebars template rendering. And vertx-rabbitmq-client provides us with our RabbitMQ consumer.
Setting Up the Web Server
Next, we need an entry point for our application.
package com.taubler.bridge;
import io.vertx.core.AbstractVerticle;
public class Main extends AbstractVerticle {
@Override
public void start() {
}
}
When we run our application, we’ll tell Vert.x that this is the main class to launch (Vert.x requires the main class to be a verticle, so we simply extend AbstractVerticle). On startup, Vert.x will create an instance of this class and call its start() method.
Next we’ll want to create a web server that listens on a specified port. The Vert.x-web add-on uses two main classes for this: HttpServer is the actual web server implementation, while Router is a class that allows requests to be routed. We’ll create both in the start() method. Also, although we don’t strictly need one, we’ll use a templating engine. Vert.x-web offers a number of options; we’ll use Handlebars here.
Let’s see what we have so far:
TemplateHandler hbsHandler = TemplateHandler.create(HandlebarsTemplateEngine.create());
@Override
public void start() {
HttpServer server = vertx.createHttpServer();
Router router = new RouterImpl(vertx);
router.get("/rsc/*").handler(ctx -> {
String fn = ctx.request().path().substring(1);
vertx.fileSystem().exists(fn, b -> {
if (b.result()) {
ctx.response().sendFile(fn);
} else {
System.out.println("Couldn’t find " + fn);
ctx.fail(404);
}
});
});
String hbsPath = ".+\.hbs";
router.getWithRegex(hbsPath).handler(hbsHandler);
router.get("/").handler(ctx -> {
ctx.reroute(“/index.hbs”);
});
// web socket code will go here
server.requestHandler(router::accept).listen(8080);
}
Let’s start with, well, the start() method. Creating the server is a simple one-liner: vertx.createHttpServer() vertx is an instance of io.vertx.core.Vertx, which is a class that is at the core of much of Vert.x’s functionality. Since our Main class extends AbstractVerticle, it inherits the member protected Vertx vertx.
Next, we’ll configure the server. Most of this work is done via a Router, which maps request paths to Handlers that process them and return the correct response. We first create an instance of RouterImpl, passing our vertx instance. This class provides a number of methods to route requests to their associated Handlers, which process the request and provide a response.
Since we’ll be serving up a number of static Javascript and CSS resources, we’ll create that handler first. The router.get(“/rsc/*”) call matches GET requests whose path starts with /rsc/ As part of Router’s fluent interface, it returns our router instance, allowing us to chain the handler() method to it. We pass that method an instance of io.vertx.core.Handler<io.vertx.ext.web.RoutingContext> in the form of a lambda expression. The lambda will look in the filesystem for the requested resource and, if found, return it, or else return a 404 status code.
Next we’ll create our second handler, to serve up dynamic HTML pages. To do this, we configure the router to route any paths that match the hbsPath regular expression, which essentially matches any paths ending in .hbs, to the io.vertx.ext.web.handler.TemplateHandler instance that we’d created as a class variable. Like our lambda above, this is an instance of Handler<RoutingContext>, but it’s written specifically to leverage a templating engine; in our case, a HandlebarsTemplateEngine. Although not strictly needed for this application, this allows us to generate dynamic HTML based on serverside data.
Last, we configure our router to internally redirect requests for / to /index.hbs, ensuring that our TemplateHandler handles them.
Now that our router is configured, we simply pass a reference to its accept() method to our server’s requestHandler() method, then (using HttpServer’s fluent API) invoke server’s listen() method, telling it to listen on port 8080. We now have a Web server listening on port 8080.
Adding Web Sockets
Next, let’s enable web sockets in our app. You’ll notice a comment in the code above; we’ll replace it with the following:
SockJSHandlerOptions options = new SockJSHandlerOptions().setHeartbeatInterval(2000);
SockJSHandler sockJSHandler = SockJSHandler.create(vertx, options);
BridgeOptions bo = new BridgeOptions()
.addInboundPermitted(new PermittedOptions().setAddress("/client.register"))
.addOutboundPermitted(new PermittedOptions().setAddress("service.ui-message"));
sockJSHandler.bridge(bo, event -> {
System.out.println("A websocket event occurred: " + event.type() + "; " + event.getRawMessage());
event.complete(true);
});
router.route("/client.register" + "/*").handler(sockJSHandler);
Our web client will use the SockJS Javascript library. Doing this makes integrating with Vert.x dirt simple, since Vert.x-web offers a SockJSHandler that does most of the work for you. The first couple of lines above creates one of those. We first create a SockJSHandlerOptions instance to set our preferences. In our case, we tell our implementation to expect a heartbeat from our web client every 2000 milliseconds; otherwise, Vert.x will close the web socket, assuming that the user has closed or navigated away from the web page. We pass our vertx instance along with our options to create a SockJSHandler, called sockJSHandler. Just like our lambda and hbsHandler above, SockJSHandler implements Handler<RoutingContext>
Next, we configure our bridge options. Here, the term “bridge” refers to the connection between our Vert.x server and the web browser. Messages are sent between the two on addresses, much like messages are passed on addresses along the event bus. Our BridgeOptions instance, then, configures on what addresses the browser can sent messages to the server (via the addInboundPermitted() method) and which the server can send to the browser (vai the addOutboundPermitted() method). In our case, we’re saying that the web browser can send messages to the server via the “/client-register” address, while the server can send messages to the browser on the “service.ui-message” address. We configure sockJSHandler’s bridge options by passing it our BridgeOptions instance, as well as a lambda representing a Handler<Event> that provides useful logging for us. Finally, we attach sockJSHandler to our router, listening for HTTP requests that match “/client.register/*”.
Consuming From the Message Queue
That covers the web server part. Let’s shift to our RabbitMQ consumer. First, we’ll write the code that creates our RabbitMQClient instance. This will be done in a RabbitClientFactory class:
public class RabbitClientFactory {
public static RabbitClientFactory RABBIT_CLIENT_FACTORY_INSTANCE = new RabbitClientFactory();
private static RabbitMQClient rabbitClient;
private RabbitClientFactory() {}
public RabbitMQClient getRabbitClient(Vertx vertx) {
if (rabbitClient == null) {
JsonObject config = new JsonObject();
config.put("uri", "amqp://dbname:password@cat.rmq.cloudamqp.com/dbname");
rabbitClient = RabbitMQClient.create(vertx, config);
}
return rabbitClient;
}
}
This code should be pretty self explanatory. The one method, getRabbitClient(), creates an instance of a RabbitMQClient, configured with the AMQP URI, assigns it to a static rabbitClient variable, and returns it. As per the typical factory pattern, a singleton instance is also created.
Next, we’ll get an instance of the client and subscribe it to listen for messages. This will be done in a separate verticle:
public class RabbitListenerVerticle extends AbstractVerticle {
private static final Logger log = LoggerFactory.getLogger(RabbitListenerVerticle.class);
@Override
public void start(Future<Void> fut) throws InterruptedException {
try {
RabbitMQClient rClient = RABBIT_CLIENT_FACTORY_INSTANCE.getRabbitClient(vertx);
rClient.start(sRes -> {
if (sRes.succeeded()) {
rClient.basicConsume("bunny.queue", "service.rabbit", bcRes -> {
if (bcRes.succeeded()) {
System.out.println("Message received: " + bcRes.result());
} else {
System.out.println("Message receipt failed: " + bcRes.cause());
}
});
} else {
System.out.println("Connection failed: " + sRes.cause());
}
});
log.info("RabbitListenerVerticle started");
fut.complete();
} catch (Throwable t) {
log.error("failed to start RabbitListenerVerticle: " + t.getMessage(), t);
fut.fail(t);
}
}
}
As with our Main verticle, we implement the start() method (accepting a Future with which we can report our success or failure with starting this verticle). We use the factory to create an instance of a RabbitMQClient, and start it using its start() method. This method takes a Handler<AsyncResult<Void>> instance which we provide as a lambda. If starting the client succeeds, we call its basicConsume() method to register it as a listener. We pass three arguments to that method. The first, “bunny.queue”, is the name of the RabbitMQ queue that we’ll be consuming from. The second, “service.rabbit”, is the name of the Vert.x event bus address to which any messages received by the client (which will be of type JsonObject) will be sent (see Figure 1 for a refresher on this concept). The last argument is again a Handler<AsyncResult<Void>>; this argument is required, but we don’t really need it, so we simply log success or failure messages.
So at this point, we have a listener that received messages from RabbitMQ and immediately sticks them on the event bus. What happens to the messages then?
Theoretically, we could allow those messages to be sent straight to the web browser to handle. However, I’ve found that it’s best to allow the server to format any data in a manner that’s most easily consumed by the browser. In our sample app, we really only care about printing the text contained within the RabbitMQ message. However, the messages themselves are complex objects. So we need a way to extract the text itself before sending it to the browser.
So, we’ll simply create another verticle to handle this:
public class RabbitMessageConverterVerticle extends AbstractVerticle {
@Override
public void start(Future<Void> fut) throws InterruptedException {
vertx.eventBus().consumer("service.rabbit", msg -> {
JsonObject m = (JsonObject) msg.body();
if (m.containsKey("body")) {
vertx.eventBus().publish("service.ui-message", m.getString("body"));
}
});
}
}
There’s not much to it. Again we extend AbstractVerticle and override its start() method. There, we gain access to the event bus by calling vertx.eventBus(), and listen for messages by calling its consumer() method. The first argument indicates the address we’re listening to; in this case, it’s “service.rabbit”, the same address that our RabbitListenerVerticle publishes to. The second argument is a Handler<Message<Object>>. We provide that as a lambda that receives a Message<Object> instance from the event bus. Since we’re listening to the address that our RabbitListenerVerticle publishes to, we know that the Object contained as the Message’s body will be of type JsonObject. So we cast it as such, find its “body” key (not to be confused with the body of the Message<Object> we just received from the event bus), and publish that to the “service.ui-message” event bus channel.
Deploying the Message Queue Verticles
So we have two new verticles designed to get messages from RabbitMQ to the “service-ui.message” address. Now we need to ensure they are started. So we simply add the following code to our Main class:
protected void deployVerticles() {
deployVerticle(RabbitListenerVerticle.class.getName());
deployVerticle(RabbitMessageConverterVerticle.class.getName());
}
protected void deployVerticle(String className) {
vertx.deployVerticle(className, res -> {
if (res.succeeded()) {
System.out.printf("Deployed %s verticle n", className);
} else {
System.out.printf("Error deploying %s verticle:%s n", className, res.cause());
}
});
}
Deploying verticles is done by calling deployVerticle() on our Vertx instance. We provide the name of the class, as well as a Handler<AsyncResult<String>>. We create a deployVerticle() method to encapsulate this, and call it to deploy each of RabbitListenerVerticle and RabbitMessageConverterVerticle from within a deployVerticles() method.
Then we add deployVerticles() to Main’s start() method.
HTML and Javascript
Our serverside implementation is done. Now we just need to create our web client. First, we create a basic HTML page, index.bhs, and add it to a templates/ folder within our web root:
<html>
<head>
<title>Messages</title>
<link rel="stylesheet" href="/rsc/css/style.css'>
<script src="https://code.jquery.com/jquery-3.1.0.min.js" integrity="sha256-cCueBR6CsyA4/9szpPfrX3s49M9vUU5BgtiJj06wt/s=" crossorigin=”anonymous”></script>
<script src="https://cdn.jsdelivr.net/sockjs/0.3.4/sockjs.min.js"></script>
<script src="/rsc/js/vertx-eventbus.js"></script>
<script type="text/javascript” src=”/rsc/js/main.js"></script>
</head>
<body>
<h1>Messages</h1>
<div id="messages"></div>
</body>
</html>
We’ll leverage the jQuery and sockjs Javascript libraries, so those scripts are imported. We’ll also import three scripts that we’ve placed in a rsc/js/ folder: main.js and websocket.js, which we’ve created, and vertx-eventbus.js, which we’ve downloaded from the Vert.x site. The other important element is a DIV of id messages. This is where the RabbitMQ messages will be displayed.
Let’s look at our main.js file:
var eventBus = null;
var eventBusOpen = false;
function initWs() {
eventBus = new EventBus(‘/client.register’);
eventBus.onopen = function () {
eventBusOpen = true;
regForMessages();
};
eventBus.onerror = function(err) {
eventBusOpen = false;
};
}
function regForMessages() {
if (eventBusOpen) {
eventBus.registerHandler('service.ui-message', function (error, message) {
if (message) {
console.info('Found message: ' + message);
var msgList = $("div#messages");
msgList.html(msgList.html() + "<div>" + message.body + "</div>");
} else if (error) {
console.error(error);
}
});
} else {
console.error("Cannot register for messages; event bus is not open");
}
}
$( document ).ready(function() {
initWs();
});
function unregister() {
reg().subscribe(null);
}
initWs() will be called when the document loads, thanks to jQuery’s document.ready() function. It will open a web socket connection on the /client.register channel (permission for which, as you recall, was explicitly granted by our BridgeOptions class).
Once it successfully opens, regForMessages()is invoked. This function invokes the Javascript representation of the Vert.x event bus, registering to listen on the “service.ui-message” address. Vert.x’s sockjs implementation provides the glue between the web socket address and its event bus address. regForMessages()also takes a callback function that accepts a messages, or an error if something went wrong. As with Vert.x event bus messages, each message received will contain a body, which in our case consists of the text to display. Our callback simply extracts the body and appends it to the messages DIV in our document.
Running the Whole Application
That’s it! Now we just need to run our app. First, of course, we need a RabbitMQ instance. You can either download a copy (https://www.rabbitmq.com/download.html) and run it locally, or use a cloud-provider such as Heroku (https://elements.heroku.com/addons/cloudamqp) Either way, be sure to create a queue called bunny.queue.
Finally, we’ll launch our Vert.x application. Since Vert.x does not require an app server, it’s easy to start up as a regular Java application. The easiest way is to just run it straight within your IDE. Since I use Eclipse, I’ll provide those steps:
- Go to the Run -> Run Configurations menu item
- Click the New Run Configurations button near the top left of the dialog
- In the right-hand panel, give the run configuration a name such as MSGQ UI Bridge
- In the Main tab, ensure that the project is set to the one in which you’d created the project
- Also in the Main tab, enter io.vertx.core.Launcher as the Main class.
- Switch to the arguments tab and add the following as the Program arguments: run com.taubler.bridge.Main –launcher-class=io.vertx.core.Launcher
- If you’re using a cloud provider such as Heroku, you might need to provide a system property representing your Rabbit MQ credentials. Do this in the Environment tab.
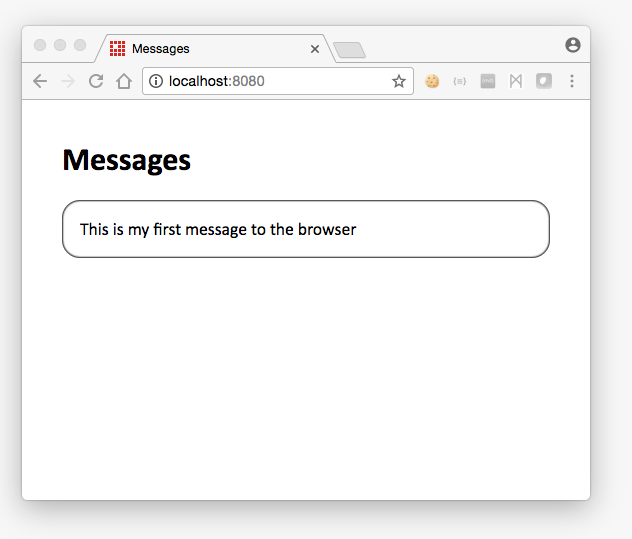
Once that’s set up, launch the run configuration. The server is listening on port 8080, so pointing a browser to http://localhost:8080 will load the index page:
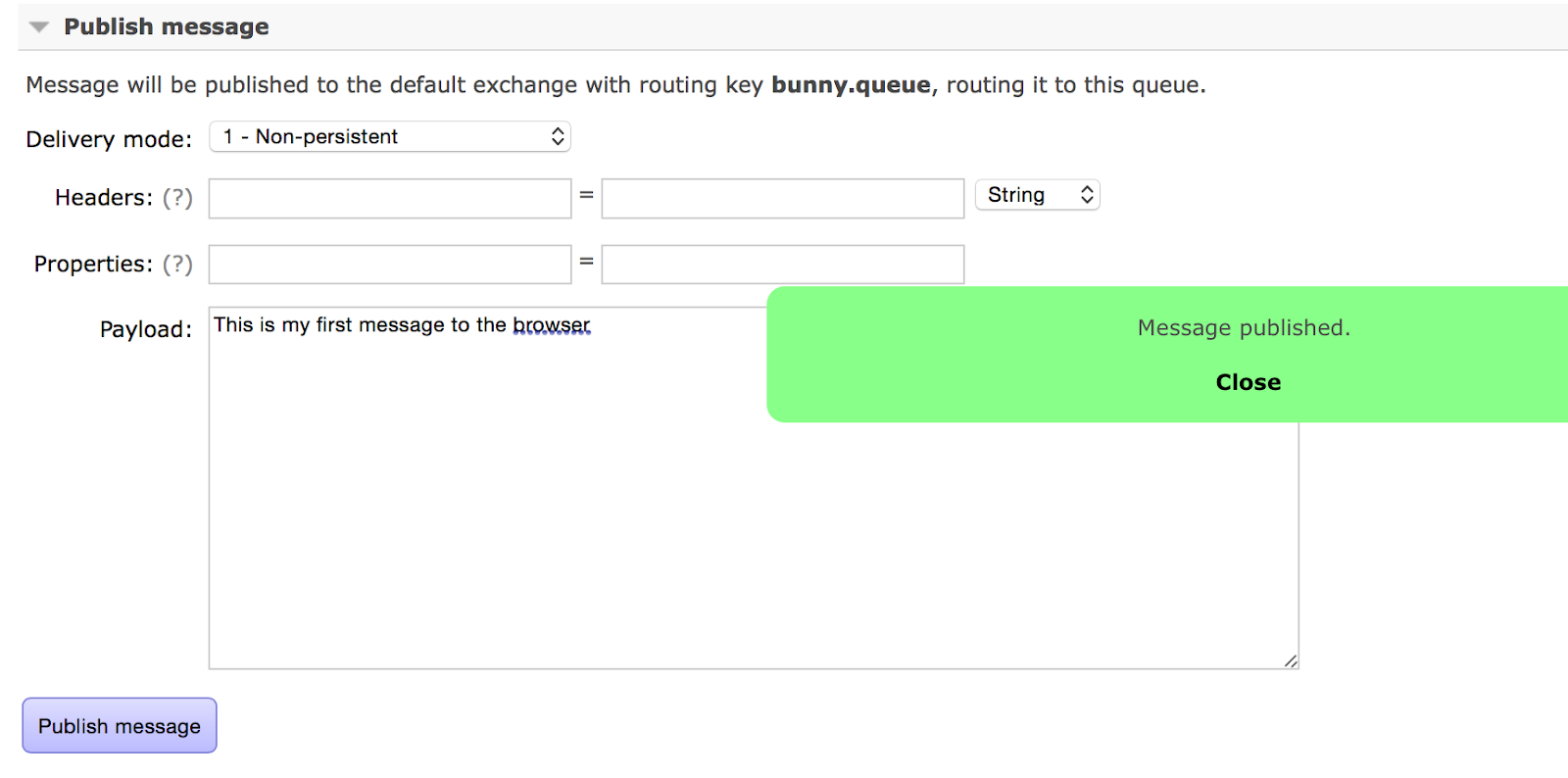
Next, go to the RabbitMQ management console’s Queues tab. Under the Publish message header, you’ll find controls allowing you to push a sample message to the queue:
Once you’ve one that, head back to the browser window. Your message will be there waiting for you!
That’s it!
I hope this post has both taught you how to work with message queues and web sockets using Vert.x, and demonstrated how easy and fun working with Vert.x can be.